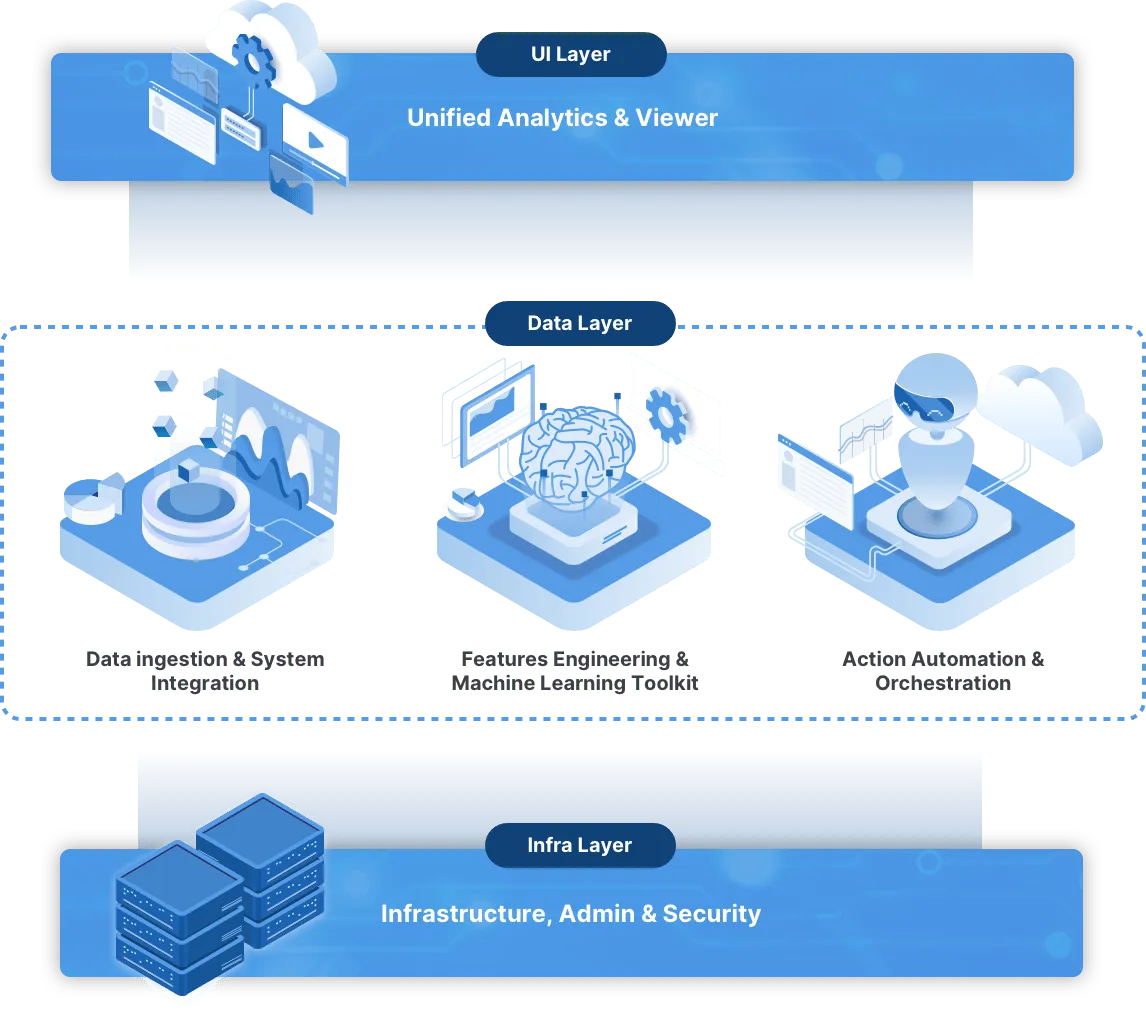
Any existing information source or hardware element.

Scalable and Highly available with minimum human intervention.

Integrated Feature Engine and ML Toolkit.

Correlate and build your own stats from raw data.

Customizable UI with Integrated Reporting.






It facilitates the creation of new UI applications from scratch, an API to connect to the different data sources and a set of ready-made widgets that can be dynamically added to configure customized views relevant to each use case in a very simple way.
More than 160 widgets available now. The list keeps growing as new widgets are added to address new required functionality.

Easy Data ingestion process of any existing information source, hardware elements or sensors, as it supports connectivity with dozens of different data endpoints via standard and custom connectors and enables formatting of those into a uniform format.
Based on Open-Source Big Data components for storing and processing big datasets in a distributed fashion on large clusters of commodity hardware. This accomplishes three goals: massive data storage, fast processing and at a low price point.

Features engine with capabilities to edit and calculate ML Features, including simple and complex definitions over other metrics of different nature as counters, KPIs, events, statistics or any other data sets.
ML Toolkit allows users to create Machine Learning models for Classification, Regression and Clustering. These models are trained using KPI/Features/Alert data that has been generated in previous stages of the Tupl Data Ingestion Pipeline

It allows the configuration and execution of external and internal actions, such as sending an email based on some criteria, integrating against a third-party ticketing system or interacting with external equipment to perform an action.
It supports two ways of configuring actions: a simple declarative way to define most of the actions and a more advanced mode that allows to write functions, also known as Function as a Service or just FaaS, in your preferred language.

It provides the necessary utilities for the efficient management of computing, storage resources, and all services in the cluster, both third party as well as Tupl proprietary services.
It leverages Kubernetes to manage the runtime resources and their usage. Also, it manages multiple underlying infrastructure services in cloud providers (AWS, GCP, Azure, Digital Ocean...), bare metal servers and private clouds.
Get started and request a demo to learn how TuplOS can help you.